Usecases
Featured Post
Latest Posts
Usecases
Featured Post
Latest Posts
Back to blogs
Marketing and Growth
Mastering Hybrid Event Tracking for Better Marketing Performance
By
Abhimanyu Atri
Marketing Product Manager
1 min read

Image by Vecteezy
Tl;DR
Browser-only tracking misses a meaningful chunk of conversions: ad blockers alone stop roughly 40% of desktop users from firing JavaScript tags, and crashes, weak connections, and disappearing cookies cut into the rest.
Hybrid tracking sends every key event from both the browser (for behavioral detail like clicks and scrolls) and the server (a signal ad blockers and network failures can't touch).
A unique event ID shared between the client and server call lets Meta, Google, and other platforms deduplicate, so each conversion is counted once instead of twice.
GTM's server-side container and Meta's Conversions API are the main tools for getting server-side events flowing to ad platforms.
Retry logic and offline event queues (especially for mobile) keep events from getting lost when servers or connections fail.
A phased rollout - starting with your top five conversion events, then expanding to full monitoring and a CDP if needed - gets teams from inaccurate ROAS to trustworthy, audit-ready conversion data.
Your Tracking Is Probably Lying to You
Not intentionally. But if you still rely on browser-based tracking alone, a meaningful chunk of your conversion data is either missing or wrong - and you likely have no idea which purchases, leads, or sign-ups never made it into your reports.
Adblockers are the most obvious culprit. Around 40% of desktop users run one. When someone with an ad blocker converts on your site, the JavaScript tag in their browser never fires. That conversion simply does not exist in your data. You optimize toward a distorted picture and wonder why your campaigns underperform.
Then there are browser crashes, unstable mobile connections, and the slow death of third-party cookies. Each one creates another hole in your data.
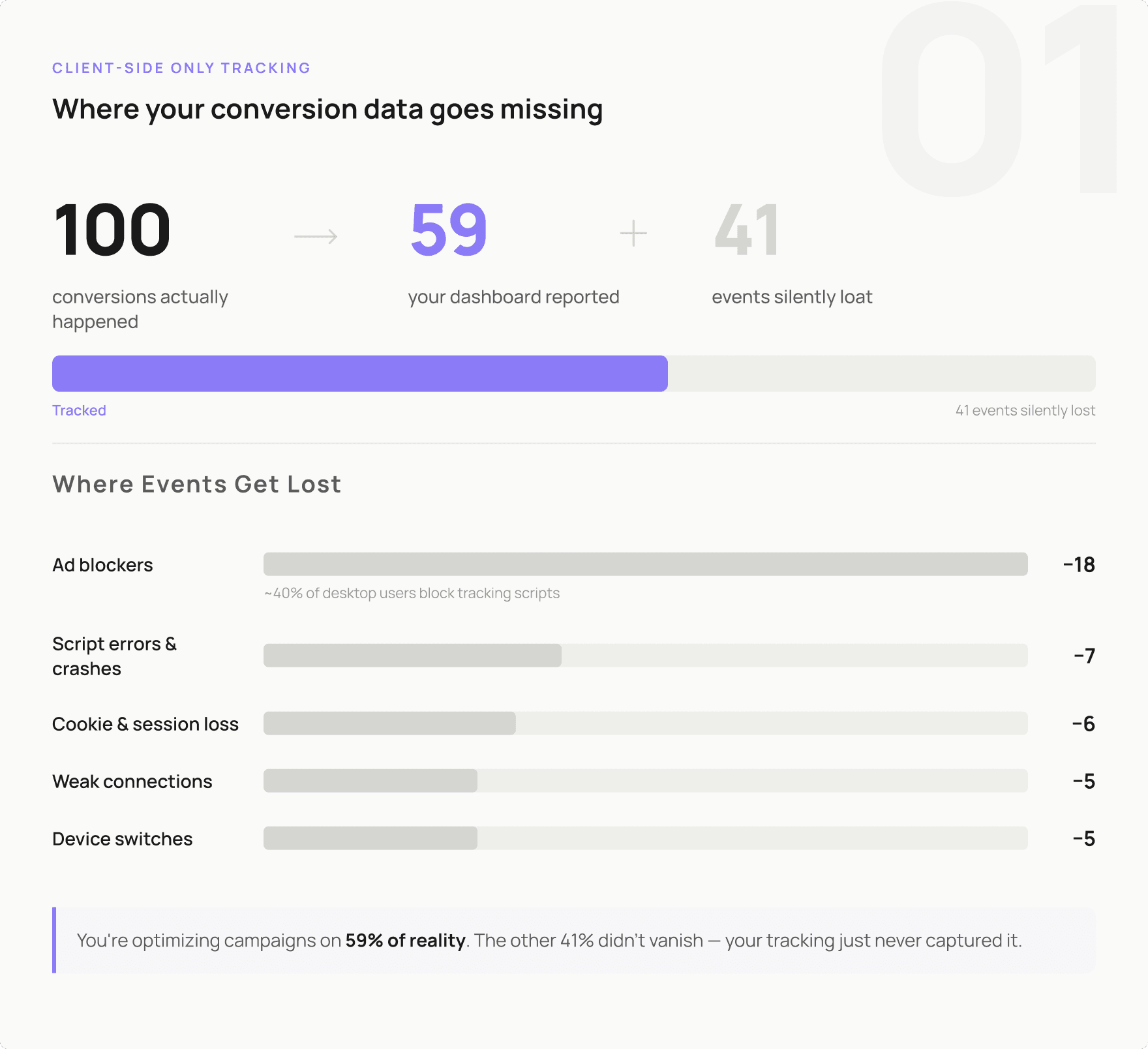
Figure 1. Where your conversion data goes missing
Hybrid event tracking patches those holes. You collect the same events from two sources - the browser and your server - so even when one fails, the other catches it. This post explains how to set it up, what to watch for, and how to get real value out of it.
What Exactly Is Hybrid Event Tracking?
The name is fairly self-explanatory, but it is worth being precise about what each side does and why you need both.
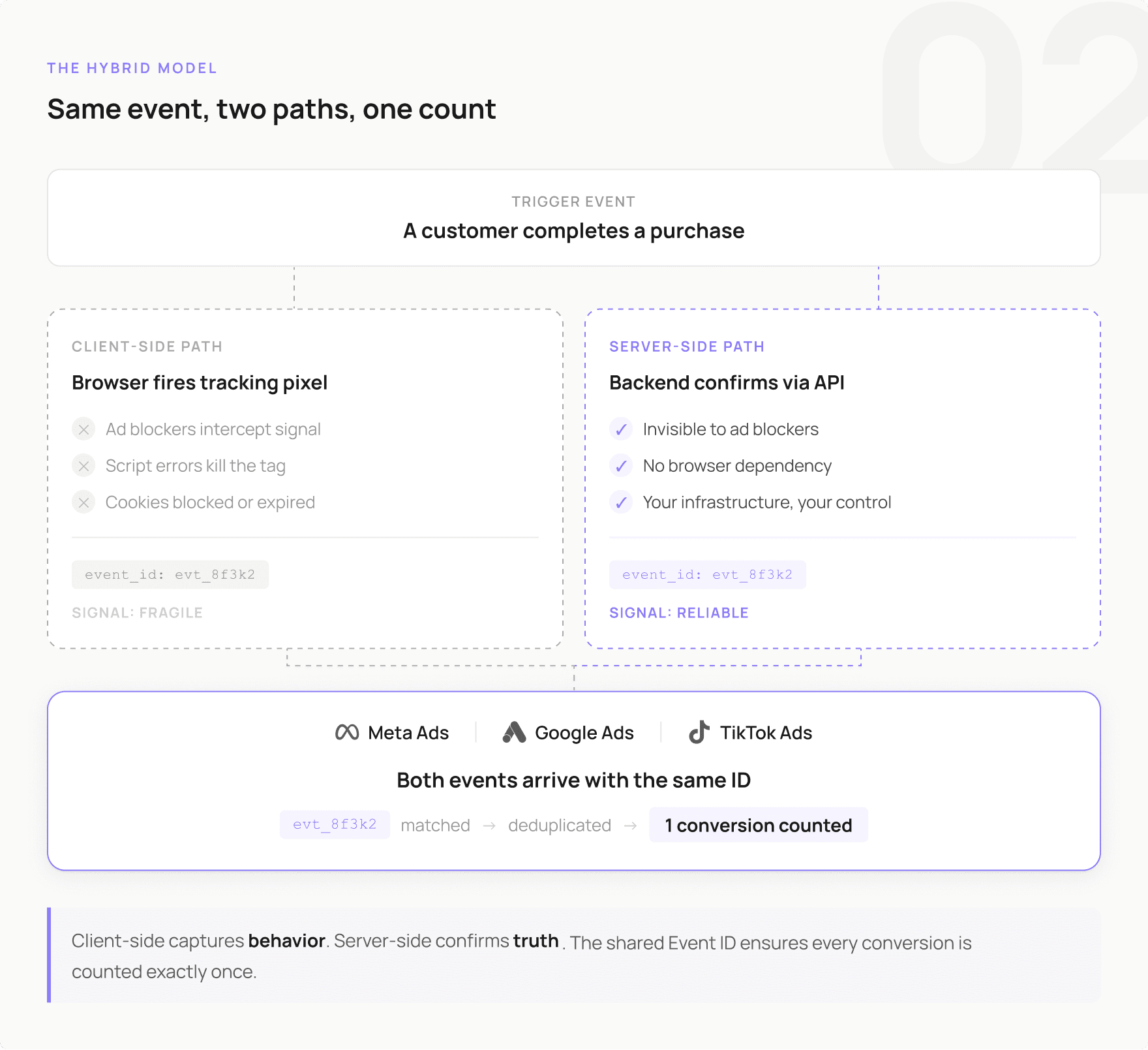
Figure 2. Hybrid event tracking model
The Client Side (Your Visitor's Browser)
Traditional tracking works by dropping a JavaScript snippet onto your site. When someone visits, their browser runs that code and sends event data to your analytics platform. Fast, real-time, and great for capturing detailed behavior - clicks, scrolls, form interactions, video plays.
The problem is that this approach depends entirely on the browser cooperating. But Ad Blockers, privacy-setting restrictions, or simple script errors create multiple failure points. On a bad connection, events get dropped before they send. You never get a callback telling you something was missed - the data just disappears.
The Server Side (Your Backend)
Server-side tracking cuts the browser out of the loop. Instead of relying on a visitor's browser to fire an event, your own server does it. When a purchase completes, your server sends that transaction data directly to Google, Meta, or wherever you need it - via their official APIs.
Because it runs on infrastructure you control, adblockers cannot touch it. Network hiccups on the visitor's end do not matter. You get a reliable, consistent signal for your most important events.
The trade-off is that it does not capture front-end behavior well. A server has no idea someone hovered over your pricing table for 15 seconds - only the browser knows that.
Why You Need Both
Client-side gives you depth of behavioral insight. Server-side gives you reliability on the events that actually drive your business. Neither is sufficient on its own. A hybrid setup plays to the strengths of each and covers the weaknesses of both.
Why Does a Hybrid Model Matter for Your Business?
Your Conversion Data Becomes Trustworthy
When your reported conversions match your actual revenue, everything downstream improves. ROAS calculations are accurate, budget allocation decisions make sense, and creative testing has a reliable signal to optimize against. Inaccurate conversion data compounds - bad data leads to bad bids, bad bids lead to bad results, and you keep adjusting the wrong variables.
Privacy Compliance Gets Easier to Manage
GDPR, CCPA, and similar regulations require you, as the website owner, to control what data leaves your systems and when. When you route events through your server, you decide exactly what gets forwarded to third-party platforms - and what stays internal. That is a much cleaner compliance posture than browser scripts scattering data around before you have a chance to audit it.
You Stop Losing High-Value Events
A purchase confirmation is the most important event your site fires. Losing even a small percentage of those to ad blockers or browser failures means your ad platforms are optimizing on an incomplete signal. Over time, that degrades campaign performance in ways that are genuinely hard to diagnose - the platform thinks it is doing better or worse than it actually is.
Which Tools Actually Do This?
The good news is that you do not need to build anything from scratch. The major platforms have already built the server-side infrastructure - you mostly need to connect things correctly.
Google Tag Manager Server-Side Container
Most people know GTM as the client-side tag manager. However, it also has a server-side container you can host on Google Cloud. Once set up, the visitor's browser fires events to the GTM server container instead of directly to Google Analytics or Meta. The container processes those events and forwards them wherever they need to go.
This gives you centralized control over all your outgoing data. You can filter, enrich, or transform events before they reach any third party. It is also where you can add server-side event calls alongside the client-side ones to add more context or enrich the data.
Meta Conversions API
If you run Facebook or Instagram ads, the Conversions API is genuinely important. It sends server-side events - purchases, registrations, custom conversions - directly to Meta, independent of whether the Pixel fired in the browser. Meta has built deduplication into the system, so when both the Pixel and the API send the same event, Meta counts it once.
Teams that implement this properly typically see their reported conversion numbers increase - not because they suddenly have more conversions, but because they were previously under-reporting them. We have written a complete breakdown of how Meta's Conversion APIs work here.
Segment, Rudderstack, and Other CDPs
If you are sending data to more than two or three platforms, a Customer Data Platform starts to make sense. It acts as a central hub: events come in once, and the CDP routes them to every downstream tool. Consistency improves, and you avoid the maintenance nightmare of separate integrations for each platform.
You can read more about CDPs in our post here.
The Deduplication Problem (And How to Solve It)
This is where a lot of hybrid setups go wrong. When you send the same event from both the browser and the server, platforms will count it twice unless you explicitly tell them not to.
Imagine a purchase fires client-side via the Pixel and server-side via the Conversions API. Without deduplication, Meta logs two purchases. Your ROAS looks fantastic, but your actual results have not changed. By the time someone notices the mismatch, you have already allocated your budget based on false signals.
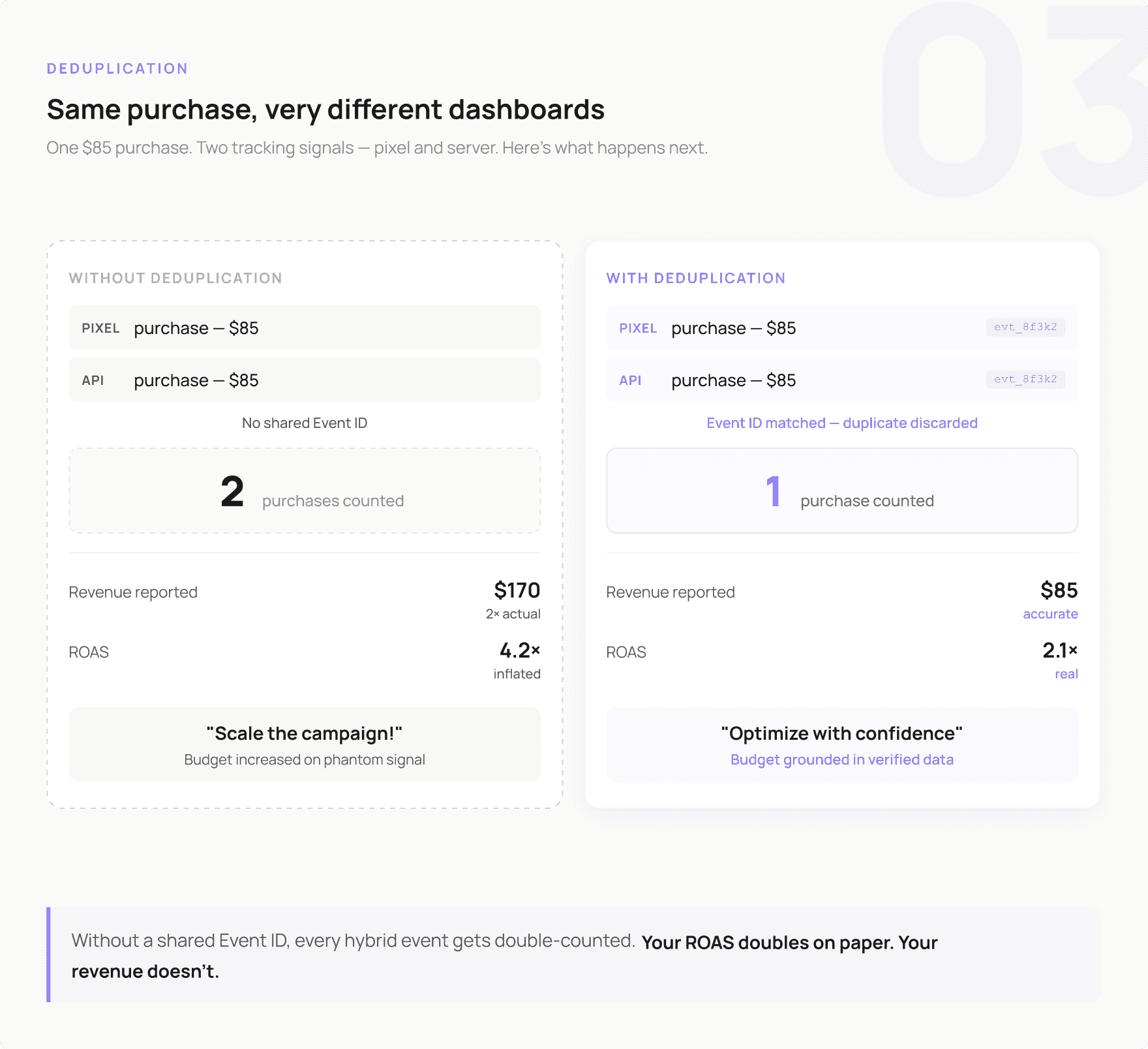
Figure 3. Data deduplication and how to solve it
The Fix: Unique Event IDs
Assign a unique ID to every event the moment it is created - usually in the browser. Both the client-side and server-side calls for that event should include the same ID. When Meta, Google, or any other platform receives two events with the same ID, it discards the duplicate and counts it once.
This sounds simple, and it is, but you have to implement it deliberately. It does not happen automatically. Generate the ID in the browser, pass it to your server in the event payload, and make sure both tracking calls include it.
Timestamps and Session IDs as Backup
Some platforms also use timestamps and session IDs as secondary deduplication signals. It is worth implementing these too, especially for events where ID generation might fail. Always log timestamps in UTC - mixing timezones creates matching problems that are tedious to debug.
What Happens When Things Break?
Servers go down. Network requests time out. Events get dropped. Building in some resilience from the start saves significant pain later.
Retry Logic
If your server sends an event to an analytics platform and does not receive a success response, it should automatically retry. Most server-side implementations support this natively, but it is worth confirming rather than assuming.
Event Queues for Mobile
Mobile apps face an additional challenge: users go offline. If someone completes a purchase while their connection drops, that event needs to be preserved. Local event queues store events on the device and push them to the server once the connection returns. This is standard practice for mobile - make sure it is in your implementation.
Monitoring Your Event Volume
Set up basic monitoring on your key conversion events. If purchase events drop by 30% overnight and revenue did not, your tracking broke. Without monitoring, you might not notice for days. A simple alert when event counts fall outside normal ranges catches most problems quickly.
What Are the Most Common Problems and How Do You Fix Them?
Client and Server Numbers Do Not Match
They never match perfectly - expect some difference, especially on low-intent events. What matters is that your high-value events (purchases, qualified leads) have low discrepancy rates. If you see a 20% gap on purchase events, something is wrong with your deduplication, or your server-side implementation is missing events.
Standardize your event names across both systems. If the client fires "purchase" and the server fires "Purchase Complete", your platforms cannot deduplicate them. One name, used consistently everywhere, solves most matching problems.
Page Speed Takes a Hit
Client-side tags add weight to your pages. A bloated tag setup can noticeably slow your site, which hurts both user experience and ad quality scores. A few things help: use GTM's server-side container to move processing off the browser, batch events where possible rather than firing individual calls, and audit your tags regularly to remove those nobody is actually using.
Multiple Teams, Multiple Tags, No Coordination
In larger organizations, the marketing team, the product team, and the analytics team all want their own tags on the same site. Without coordination, you end up with duplicate events, conflicting implementations, and nobody quite sure what is actually firing. Version control for your tag configurations, a shared naming convention, and a staging environment for testing changes before they go live will prevent most of these issues.
Three Examples of Hybrid Tracking Working in Practice
E-Commerce: Tracking the Full Purchase Funnel
A user lands on a product page and adds some items to their cart over two sessions. They eventually check out on the third session. Your client-side tracking captures every step of that behavioral journey - cart adds, removal, page revisits. When the purchase completes, both the browser and the server fire a purchase event with the same unique transaction ID. Deduplication catches duplicates, the ad platform logs one conversion, and your ROAS reflects actual sales.
The cart abandonment data from the client-side feeds your retargeting campaigns. The confirmed purchase data from the server side feeds your conversion optimization. Both are essential.
B2B Lead Gen: Knowing Which Leads Actually Made It
Consider an example of a visitor filling out a contact form on your website. But they never submitted: they started filling in the form, paused on the phone number field, and almost left before completing it. That behavioral data is useful for form optimization. The server-side layer verifies whether the lead has been added to your CRM. This keeps your campaign reporting clear. It only reflects actual qualified leads, not form views or random clicks on the submit button of an empty/incomplete form.
Multi-Session B2B Journeys
Enterprise buyers rarely convert in a single session. They read your blog, attend a webinar, download a case study, and request a demo three weeks later - often across multiple devices. Your tracking captures the lead's path throughout your funnel, but it is a combination of client-side and server-side events. Connecting these within a CDP or data warehouse gives your sales team a coherent view of what drove pipeline activity.
Where to Start: A Practical Action Plan
This Week:
List your five most important conversion events. These are the ones you want to get right first.
Audit your current client-side setup. Are you already using GTM? Does your Meta Pixel include the fbclid and event ID parameters? Know what you have before you add anything.
Decide on a unique event ID format and document it. This needs to be consistent before you build anything else.
This Month:
Set up a GTM server-side container or connect the Meta Conversions API for at least one of the conversion events you shortlisted above. Validate that deduplication is working before expanding on these.
Add basic monitoring and alerts for your key events. Even a simple alert when daily purchase events drop below a threshold is better than nothing.
Always do a set of staging tests before deploying.
Over the Next Quarter
Expand server-side events to cover all high-value actions across your ad platforms.
Evaluate whether a CDP makes sense for your stack. If you have more than three or four downstream destinations for your event data, it probably does.
Run a data quality review. Compare your reported conversions against your actual revenue or CRM entries. The gap tells you how much your tracking has improved - and how much room is left.
The Honest Truth About Hybrid Tracking
It is not a magic fix, and it does take real effort to implement properly. You will find edge cases, discrepancies you did not expect, and events that need to be rethought once you see the server-side data alongside the client-side data.
But once it is working, it changes how you operate. You trust your data. You make budget decisions with confidence. You stop second-guessing whether a campaign is performing or whether your tracking is just broken.
That shift from uncertain to confident in your measurement is what makes this worth the investment.
Frequently Asked Questions
Do I need a developer to set this up?
For the initial build, yes - most setups require someone who can write server-side code, configure API connections, and handle event payloads. GTM's server-side container reduces the ongoing need for developer involvement but getting it set up correctly the first time is not a no-code task. Budget for it properly and you will save yourself a lot of rework.
Will server-side tracking let me ignore consent requirements?
No. Server-side tracking gives you more control over data handling, but it does not exempt you from consent obligations. If a user opts out, your server-side implementation still needs to respect that. The difference is that with server-side tracking, you have a cleaner, more auditable way to enforce those preferences.
How do I know if deduplication is working?
Check the event match rates in your ad platforms. Meta, for example, shows you what percentage of events were deduplicated. If you are sending events from both Pixel and API and seeing a 0% dedup rate, something is wrong with your event ID implementation. A healthy setup typically deduplicates 20-50% of events, depending on how reliably the Pixel fires.
What events belong on the client side versus the server side?
Client side: anything behavioral - clicks, scrolls, hovers, video engagement, partial form interactions, time on page. Server side: anything that confirms a completed action with back-end significance - purchases, form submissions that write to your CRM, account creations, subscription starts or cancellations. When both sides can capture the same event, send from both with deduplication enabled.
How much does this cost to run?
GTM's server-side container costs money to host - Google Cloud charges based on request volume, typically a few dollars a month for smaller sites and potentially more for high-traffic e-commerce. Meta Conversions API is free to use. The bigger cost is usually the developer time to set it up and maintain it. For most businesses, that cost pays back quickly in improved campaign performance.
My client and server numbers are slightly different. Is that a problem?
Small differences are normal and expected. The browser will always miss some events - crashes, adblockers, users closing tabs mid-fire. As long as your discrepancy on high-value events stays below roughly 5-10%, your setup is likely working well. Large discrepancies on purchase events specifically are worth investigating, since that is where measurement accuracy matters most.
Should I do this for a small business, or is it overkill?
It depends on how much you spend on paid ads. If you are spending a few hundred dollars a month, the implementation overhead probably is not worth it yet. If you are spending a few thousand dollars a month or more, even a modest improvement in measurement accuracy starts to pay for the setup. A rough rule: if inaccurate conversion data could cause you to misallocate more than the cost of implementation, it is worth doing.
How do I handle this across web and mobile?
The principles are the same. Your app is the client side; your backend API is the server side. The main additional consideration for mobile is offline event queuing - you need a way to store events locally when the user is offline and sync them when connectivity returns. Make sure your event naming is consistent across web and mobile or you will end up with fragmented reporting.
What is a server-side container and how is it different from a regular GTM container?
A regular GTM container runs in the visitor's browser. A server-side container runs on a server you control - usually Google Cloud for GTM's implementation. Browser events get sent to your server container, which processes them and forwards them to third-party tools. The key benefit is that the data goes through your infrastructure first, giving you control over what leaves and reducing your exposure to browser-side blocking.
How long does it take to set up?
A basic setup - one ad platform, one critical conversion event, deduplication working - typically takes a developer one to three days. A full implementation covering multiple platforms, all key events, and proper monitoring is more like two to four weeks. The variance depends mostly on how complex your existing tag setup is and whether you have a clean event taxonomy to build from.
The recommended path is to start with the most basic and fundamental events: add to carts, remove from cart, product views and conversions. Let that setup run for a few weeks to catch any bugs and then slowly expand. The time invested in the initial setup will save a lot of excess spend and effort in the future.Do I need a CDP or can I manage without one?
You can absolutely manage without one, especially early on. GTM server-side plus direct API connections to your ad platforms handles most needs. A CDP becomes worth considering when you have many downstream destinations, when multiple teams need access to the same event data, or when you want to do cross-channel attribution that requires joining data across sources. It is an upgrade, not a prerequisite.
What should I check during a tracking audit?
Start with your most important conversion events. Confirm they are firing on both client and server. Check deduplication rates. Compare reported conversions against your actual back-end records - your order management system or CRM. Look for events that fire more than once per session when they should fire once. Check that your event naming is consistent. Then look at page speed to make sure your tag setup is not hurting performance. That covers the most common failure modes.
Your Tracking Is Probably Lying to You
Not intentionally. But if you still rely on browser-based tracking alone, a meaningful chunk of your conversion data is either missing or wrong - and you likely have no idea which purchases, leads, or sign-ups never made it into your reports.
Adblockers are the most obvious culprit. Around 40% of desktop users run one. When someone with an ad blocker converts on your site, the JavaScript tag in their browser never fires. That conversion simply does not exist in your data. You optimize toward a distorted picture and wonder why your campaigns underperform.
Then there are browser crashes, unstable mobile connections, and the slow death of third-party cookies. Each one creates another hole in your data.
Figure 1. Where your conversion data goes missing
Hybrid event tracking patches those holes. You collect the same events from two sources - the browser and your server - so even when one fails, the other catches it. This post explains how to set it up, what to watch for, and how to get real value out of it.
What Exactly Is Hybrid Event Tracking?
The name is fairly self-explanatory, but it is worth being precise about what each side does and why you need both.
Figure 2. Hybrid event tracking model
The Client Side (Your Visitor's Browser)
Traditional tracking works by dropping a JavaScript snippet onto your site. When someone visits, their browser runs that code and sends event data to your analytics platform. Fast, real-time, and great for capturing detailed behavior - clicks, scrolls, form interactions, video plays.
The problem is that this approach depends entirely on the browser cooperating. But Ad Blockers, privacy-setting restrictions, or simple script errors create multiple failure points. On a bad connection, events get dropped before they send. You never get a callback telling you something was missed - the data just disappears.
The Server Side (Your Backend)
Server-side tracking cuts the browser out of the loop. Instead of relying on a visitor's browser to fire an event, your own server does it. When a purchase completes, your server sends that transaction data directly to Google, Meta, or wherever you need it - via their official APIs.
Because it runs on infrastructure you control, adblockers cannot touch it. Network hiccups on the visitor's end do not matter. You get a reliable, consistent signal for your most important events.
The trade-off is that it does not capture front-end behavior well. A server has no idea someone hovered over your pricing table for 15 seconds - only the browser knows that.
Why You Need Both
Client-side gives you depth of behavioral insight. Server-side gives you reliability on the events that actually drive your business. Neither is sufficient on its own. A hybrid setup plays to the strengths of each and covers the weaknesses of both.
Why Does a Hybrid Model Matter for Your Business?
Your Conversion Data Becomes Trustworthy
When your reported conversions match your actual revenue, everything downstream improves. ROAS calculations are accurate, budget allocation decisions make sense, and creative testing has a reliable signal to optimize against. Inaccurate conversion data compounds - bad data leads to bad bids, bad bids lead to bad results, and you keep adjusting the wrong variables.
Privacy Compliance Gets Easier to Manage
GDPR, CCPA, and similar regulations require you, as the website owner, to control what data leaves your systems and when. When you route events through your server, you decide exactly what gets forwarded to third-party platforms - and what stays internal. That is a much cleaner compliance posture than browser scripts scattering data around before you have a chance to audit it.
You Stop Losing High-Value Events
A purchase confirmation is the most important event your site fires. Losing even a small percentage of those to ad blockers or browser failures means your ad platforms are optimizing on an incomplete signal. Over time, that degrades campaign performance in ways that are genuinely hard to diagnose - the platform thinks it is doing better or worse than it actually is.
Which Tools Actually Do This?
The good news is that you do not need to build anything from scratch. The major platforms have already built the server-side infrastructure - you mostly need to connect things correctly.
Google Tag Manager Server-Side Container
Most people know GTM as the client-side tag manager. However, it also has a server-side container you can host on Google Cloud. Once set up, the visitor's browser fires events to the GTM server container instead of directly to Google Analytics or Meta. The container processes those events and forwards them wherever they need to go.
This gives you centralized control over all your outgoing data. You can filter, enrich, or transform events before they reach any third party. It is also where you can add server-side event calls alongside the client-side ones to add more context or enrich the data.
Meta Conversions API
If you run Facebook or Instagram ads, the Conversions API is genuinely important. It sends server-side events - purchases, registrations, custom conversions - directly to Meta, independent of whether the Pixel fired in the browser. Meta has built deduplication into the system, so when both the Pixel and the API send the same event, Meta counts it once.
Teams that implement this properly typically see their reported conversion numbers increase - not because they suddenly have more conversions, but because they were previously under-reporting them. We have written a complete breakdown of how Meta's Conversion APIs work here.
Segment, Rudderstack, and Other CDPs
If you are sending data to more than two or three platforms, a Customer Data Platform starts to make sense. It acts as a central hub: events come in once, and the CDP routes them to every downstream tool. Consistency improves, and you avoid the maintenance nightmare of separate integrations for each platform.
You can read more about CDPs in our post here.
The Deduplication Problem (And How to Solve It)
This is where a lot of hybrid setups go wrong. When you send the same event from both the browser and the server, platforms will count it twice unless you explicitly tell them not to.
Imagine a purchase fires client-side via the Pixel and server-side via the Conversions API. Without deduplication, Meta logs two purchases. Your ROAS looks fantastic, but your actual results have not changed. By the time someone notices the mismatch, you have already allocated your budget based on false signals.
Figure 3. Data deduplication and how to solve it
The Fix: Unique Event IDs
Assign a unique ID to every event the moment it is created - usually in the browser. Both the client-side and server-side calls for that event should include the same ID. When Meta, Google, or any other platform receives two events with the same ID, it discards the duplicate and counts it once.
This sounds simple, and it is, but you have to implement it deliberately. It does not happen automatically. Generate the ID in the browser, pass it to your server in the event payload, and make sure both tracking calls include it.
Timestamps and Session IDs as Backup
Some platforms also use timestamps and session IDs as secondary deduplication signals. It is worth implementing these too, especially for events where ID generation might fail. Always log timestamps in UTC - mixing timezones creates matching problems that are tedious to debug.
What Happens When Things Break?
Servers go down. Network requests time out. Events get dropped. Building in some resilience from the start saves significant pain later.
Retry Logic
If your server sends an event to an analytics platform and does not receive a success response, it should automatically retry. Most server-side implementations support this natively, but it is worth confirming rather than assuming.
Event Queues for Mobile
Mobile apps face an additional challenge: users go offline. If someone completes a purchase while their connection drops, that event needs to be preserved. Local event queues store events on the device and push them to the server once the connection returns. This is standard practice for mobile - make sure it is in your implementation.
Monitoring Your Event Volume
Set up basic monitoring on your key conversion events. If purchase events drop by 30% overnight and revenue did not, your tracking broke. Without monitoring, you might not notice for days. A simple alert when event counts fall outside normal ranges catches most problems quickly.
What Are the Most Common Problems and How Do You Fix Them?
Client and Server Numbers Do Not Match
They never match perfectly - expect some difference, especially on low-intent events. What matters is that your high-value events (purchases, qualified leads) have low discrepancy rates. If you see a 20% gap on purchase events, something is wrong with your deduplication, or your server-side implementation is missing events.
Standardize your event names across both systems. If the client fires "purchase" and the server fires "Purchase Complete", your platforms cannot deduplicate them. One name, used consistently everywhere, solves most matching problems.
Page Speed Takes a Hit
Client-side tags add weight to your pages. A bloated tag setup can noticeably slow your site, which hurts both user experience and ad quality scores. A few things help: use GTM's server-side container to move processing off the browser, batch events where possible rather than firing individual calls, and audit your tags regularly to remove those nobody is actually using.
Multiple Teams, Multiple Tags, No Coordination
In larger organizations, the marketing team, the product team, and the analytics team all want their own tags on the same site. Without coordination, you end up with duplicate events, conflicting implementations, and nobody quite sure what is actually firing. Version control for your tag configurations, a shared naming convention, and a staging environment for testing changes before they go live will prevent most of these issues.
Three Examples of Hybrid Tracking Working in Practice
E-Commerce: Tracking the Full Purchase Funnel
A user lands on a product page and adds some items to their cart over two sessions. They eventually check out on the third session. Your client-side tracking captures every step of that behavioral journey - cart adds, removal, page revisits. When the purchase completes, both the browser and the server fire a purchase event with the same unique transaction ID. Deduplication catches duplicates, the ad platform logs one conversion, and your ROAS reflects actual sales.
The cart abandonment data from the client-side feeds your retargeting campaigns. The confirmed purchase data from the server side feeds your conversion optimization. Both are essential.
B2B Lead Gen: Knowing Which Leads Actually Made It
Consider an example of a visitor filling out a contact form on your website. But they never submitted: they started filling in the form, paused on the phone number field, and almost left before completing it. That behavioral data is useful for form optimization. The server-side layer verifies whether the lead has been added to your CRM. This keeps your campaign reporting clear. It only reflects actual qualified leads, not form views or random clicks on the submit button of an empty/incomplete form.
Multi-Session B2B Journeys
Enterprise buyers rarely convert in a single session. They read your blog, attend a webinar, download a case study, and request a demo three weeks later - often across multiple devices. Your tracking captures the lead's path throughout your funnel, but it is a combination of client-side and server-side events. Connecting these within a CDP or data warehouse gives your sales team a coherent view of what drove pipeline activity.
Where to Start: A Practical Action Plan
This Week:
List your five most important conversion events. These are the ones you want to get right first.
Audit your current client-side setup. Are you already using GTM? Does your Meta Pixel include the fbclid and event ID parameters? Know what you have before you add anything.
Decide on a unique event ID format and document it. This needs to be consistent before you build anything else.
This Month:
Set up a GTM server-side container or connect the Meta Conversions API for at least one of the conversion events you shortlisted above. Validate that deduplication is working before expanding on these.
Add basic monitoring and alerts for your key events. Even a simple alert when daily purchase events drop below a threshold is better than nothing.
Always do a set of staging tests before deploying.
Over the Next Quarter
Expand server-side events to cover all high-value actions across your ad platforms.
Evaluate whether a CDP makes sense for your stack. If you have more than three or four downstream destinations for your event data, it probably does.
Run a data quality review. Compare your reported conversions against your actual revenue or CRM entries. The gap tells you how much your tracking has improved - and how much room is left.
The Honest Truth About Hybrid Tracking
It is not a magic fix, and it does take real effort to implement properly. You will find edge cases, discrepancies you did not expect, and events that need to be rethought once you see the server-side data alongside the client-side data.
But once it is working, it changes how you operate. You trust your data. You make budget decisions with confidence. You stop second-guessing whether a campaign is performing or whether your tracking is just broken.
That shift from uncertain to confident in your measurement is what makes this worth the investment.
Frequently Asked Questions
Do I need a developer to set this up?
For the initial build, yes - most setups require someone who can write server-side code, configure API connections, and handle event payloads. GTM's server-side container reduces the ongoing need for developer involvement but getting it set up correctly the first time is not a no-code task. Budget for it properly and you will save yourself a lot of rework.
Will server-side tracking let me ignore consent requirements?
No. Server-side tracking gives you more control over data handling, but it does not exempt you from consent obligations. If a user opts out, your server-side implementation still needs to respect that. The difference is that with server-side tracking, you have a cleaner, more auditable way to enforce those preferences.
How do I know if deduplication is working?
Check the event match rates in your ad platforms. Meta, for example, shows you what percentage of events were deduplicated. If you are sending events from both Pixel and API and seeing a 0% dedup rate, something is wrong with your event ID implementation. A healthy setup typically deduplicates 20-50% of events, depending on how reliably the Pixel fires.
What events belong on the client side versus the server side?
Client side: anything behavioral - clicks, scrolls, hovers, video engagement, partial form interactions, time on page. Server side: anything that confirms a completed action with back-end significance - purchases, form submissions that write to your CRM, account creations, subscription starts or cancellations. When both sides can capture the same event, send from both with deduplication enabled.
How much does this cost to run?
GTM's server-side container costs money to host - Google Cloud charges based on request volume, typically a few dollars a month for smaller sites and potentially more for high-traffic e-commerce. Meta Conversions API is free to use. The bigger cost is usually the developer time to set it up and maintain it. For most businesses, that cost pays back quickly in improved campaign performance.
My client and server numbers are slightly different. Is that a problem?
Small differences are normal and expected. The browser will always miss some events - crashes, adblockers, users closing tabs mid-fire. As long as your discrepancy on high-value events stays below roughly 5-10%, your setup is likely working well. Large discrepancies on purchase events specifically are worth investigating, since that is where measurement accuracy matters most.
Should I do this for a small business, or is it overkill?
It depends on how much you spend on paid ads. If you are spending a few hundred dollars a month, the implementation overhead probably is not worth it yet. If you are spending a few thousand dollars a month or more, even a modest improvement in measurement accuracy starts to pay for the setup. A rough rule: if inaccurate conversion data could cause you to misallocate more than the cost of implementation, it is worth doing.
How do I handle this across web and mobile?
The principles are the same. Your app is the client side; your backend API is the server side. The main additional consideration for mobile is offline event queuing - you need a way to store events locally when the user is offline and sync them when connectivity returns. Make sure your event naming is consistent across web and mobile or you will end up with fragmented reporting.
What is a server-side container and how is it different from a regular GTM container?
A regular GTM container runs in the visitor's browser. A server-side container runs on a server you control - usually Google Cloud for GTM's implementation. Browser events get sent to your server container, which processes them and forwards them to third-party tools. The key benefit is that the data goes through your infrastructure first, giving you control over what leaves and reducing your exposure to browser-side blocking.
How long does it take to set up?
A basic setup - one ad platform, one critical conversion event, deduplication working - typically takes a developer one to three days. A full implementation covering multiple platforms, all key events, and proper monitoring is more like two to four weeks. The variance depends mostly on how complex your existing tag setup is and whether you have a clean event taxonomy to build from.
The recommended path is to start with the most basic and fundamental events: add to carts, remove from cart, product views and conversions. Let that setup run for a few weeks to catch any bugs and then slowly expand. The time invested in the initial setup will save a lot of excess spend and effort in the future.Do I need a CDP or can I manage without one?
You can absolutely manage without one, especially early on. GTM server-side plus direct API connections to your ad platforms handles most needs. A CDP becomes worth considering when you have many downstream destinations, when multiple teams need access to the same event data, or when you want to do cross-channel attribution that requires joining data across sources. It is an upgrade, not a prerequisite.
What should I check during a tracking audit?
Start with your most important conversion events. Confirm they are firing on both client and server. Check deduplication rates. Compare reported conversions against your actual back-end records - your order management system or CRM. Look for events that fire more than once per session when they should fire once. Check that your event naming is consistent. Then look at page speed to make sure your tag setup is not hurting performance. That covers the most common failure modes.
Share:
Share:

Abhimanyu Atri
Marketing Product Manager
Marketing Product Manager at Attryb, Abhimanyu is the newest addition to the team. A passionate marketer, he helps clients improve the performance of their campaigns and achieve their goals. He's also an avid gamer.


Boost Sales Now
Join the leading D2C brands leveraging Attryb to deliver personalized experiences that drive measurable growth

Boost Sales Now
Join the leading D2C brands leveraging Attryb to deliver personalized experiences that drive measurable growth
Boost Sales Now
Join the leading D2C brands leveraging Attryb to deliver personalized experiences that drive measurable growth
Keep Reading





Load More